- Zero
- Random
- Xavier initialisation (Glorot Initialisation)
Weights are initialised from a distribution with zero mean and a specific variance designed to keep the scale of gradients roughly the same across layers.
➕ good for tanh and sigmoid
➖ not good for relu
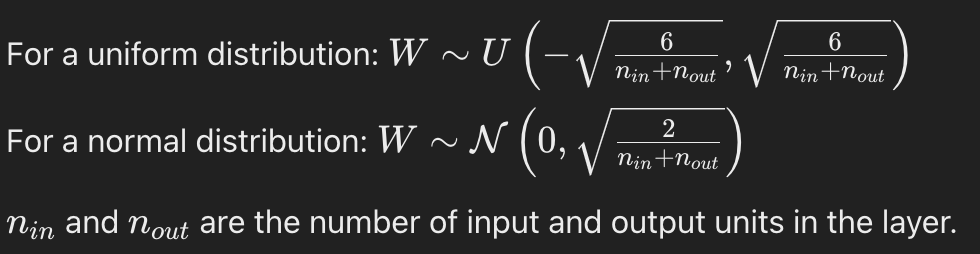
- He Initialisation (Kaiming Initialisation)
Similar to Xavier initialization but with a higher variance to account for the rectified linear units (ReLU) activations.
➖ can lead to exploding gradient in deep deep networks

- LeCun Initialisation
Designed for activation functions like sigmoid and tanh.
➕ suitable for sigmoid/tanh activations
➖ not good for relu
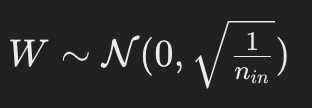
- Orthogonal Initialisation
Weights are initialized to be orthogonal matrices
➕ preserves the variance of the activations.
➖ expensive computation wise
- Variational Initialisation
Weights are sampled from a probability distribution, often Gaussian, and the parameters of this distribution are learned during training.
➕ can adapt to the data during training.
➖ more complex and requires tuning.
Few other techniques include uniform initialisation, scaled initialisation and Layer-sequential Unit-variance (LSUV) initialisation.